I analyzed 1,000 Hacker News front-page stories, long titles win and AI eats a quarter of the attention
Everyone has a theory about what hits the Hacker News front page: punchy titles, Show HN, post early. I stopped guessing and pulled 1,000 stories from the last 30 days through the public Algolia API. The data killed two of my own assumptions.
What
I fetched every HN story from the last 30 days that cleared 100 points, 1,000 of them, with their points, comment counts, post time, domain and title. Then I ran the statistics.
The headline numbers:
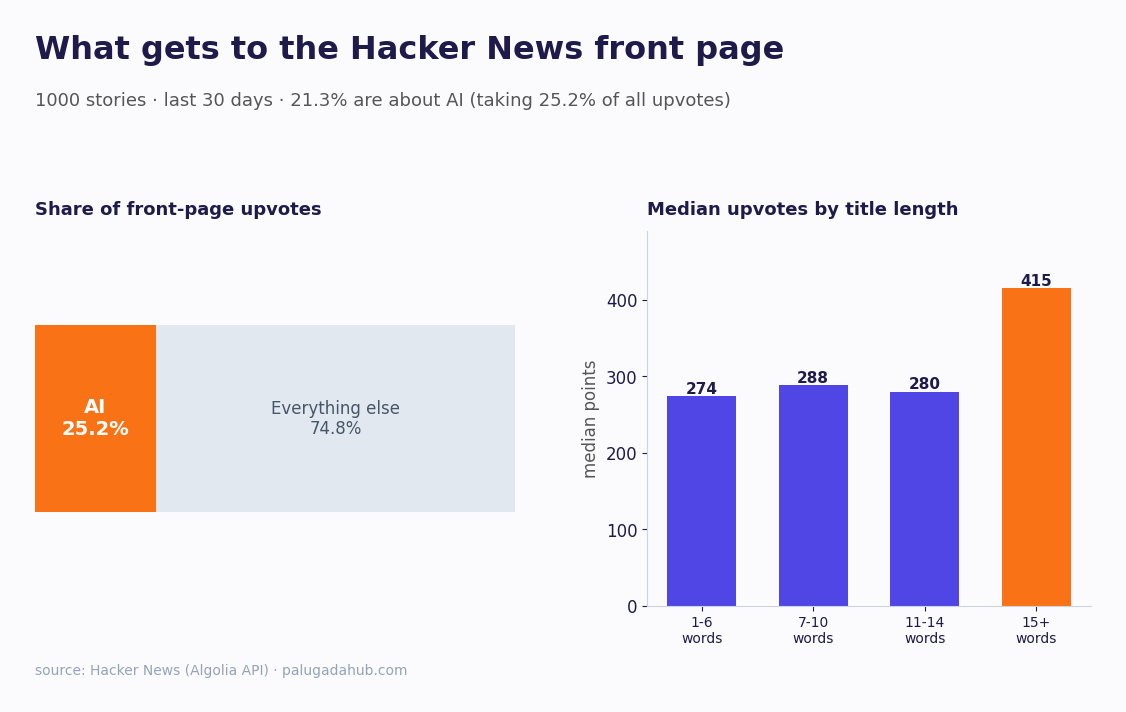
- 1 in 5 front-page stories is about AI (21.3%), and they pull 25.2% of all upvotes. AI punches above its weight on attention.
- Long titles win. Stories with 15+ word titles had a median of 415 points, versus ~274-288 for shorter ones. The "keep it punchy" advice is wrong here.
- GitHub is the single biggest source (57 stories), ahead of Twitter/X (19), TechCrunch (15) and anthropic.com (10).
- Show HN slightly beats the field, median 295 points vs 281 for regular links, 248 for Ask HN.
- Median front-page story: 281 points. Only 2% were text-only posts.
Why it matters
If you ship developer products, write technical content, or launch on HN, you're optimizing against folklore. The data says two counterintuitive things: a specific, longer title outperforms a clever short one, and AI is not "a trend", it's a quarter of the room. If you're not in tech-adjacent AI, you're competing for the remaining 75% of attention.
Who it's for
Indie hackers and founders planning a Show HN, devrel and technical writers picking headlines, and anyone who keeps hearing "just post early and keep the title short" without evidence.
When & where
The points-by-hour data peaks at 11:00 and 21:00 UTC (early morning + evening US time), but timing was a weaker signal than title and topic. What you post and how you frame it mattered more than when.
How
No scraping, no key, the HN Algolia API is open:
import urllib.request, urllib.parse, json, time
cutoff = int(time.time()) - 30*24*3600
qs = urllib.parse.urlencode({
"tags": "story",
"numericFilters": f"created_at_i>{cutoff},points>100",
"hitsPerPage": 1000,
})
hits = json.load(urllib.request.urlopen(
"https://hn.algolia.com/api/v1/search?" + qs)).get("hits", [])
# then: group by AI-keyword regex, title word-count buckets, domain, hour → median points
One honest caveat: this is survivorship data, only stories that already cleared 100 points. It tells you what front-page winners look like, not your odds of getting there. The long-title effect is partly that detailed titles often wrap big launches and deep write-ups, not that padding a title helps.
The takeaway
Stop optimizing your HN title for brevity. Be specific, be substantive, and accept that you're sharing the room with AI, which now owns a quarter of it.
Data: Hacker News via the Algolia API, last 30 days, stories above 100 points. Chart and method are reproducible, the snippet above is the whole fetch.
Building an AI agent?
I'm packaging how I ship them into one kit. Early access:
AI Agent Starter Kit →