We Built Our Own Bluesky Feed on a Cloudflare Worker. Here Is the Whole Journey, the Architecture, and the One Gotcha That Bit Us.
For a while the site just cross-posted to Bluesky: write a thing, push a copy to the timeline, done. That is broadcasting. It is not being part of the network. ATproto, the protocol under Bluesky, lets you do something better: publish your own feed, a thing other people can subscribe to inside their Bluesky app, served by code you control. So we built one. This is the full journey, the architecture, and the single bug that cost us a few minutes.
The result is live: a Palugada feed served by a Cloudflare Worker, curated by a hashtag, verified end to end through Bluesky's own infrastructure.
What a feed generator actually is
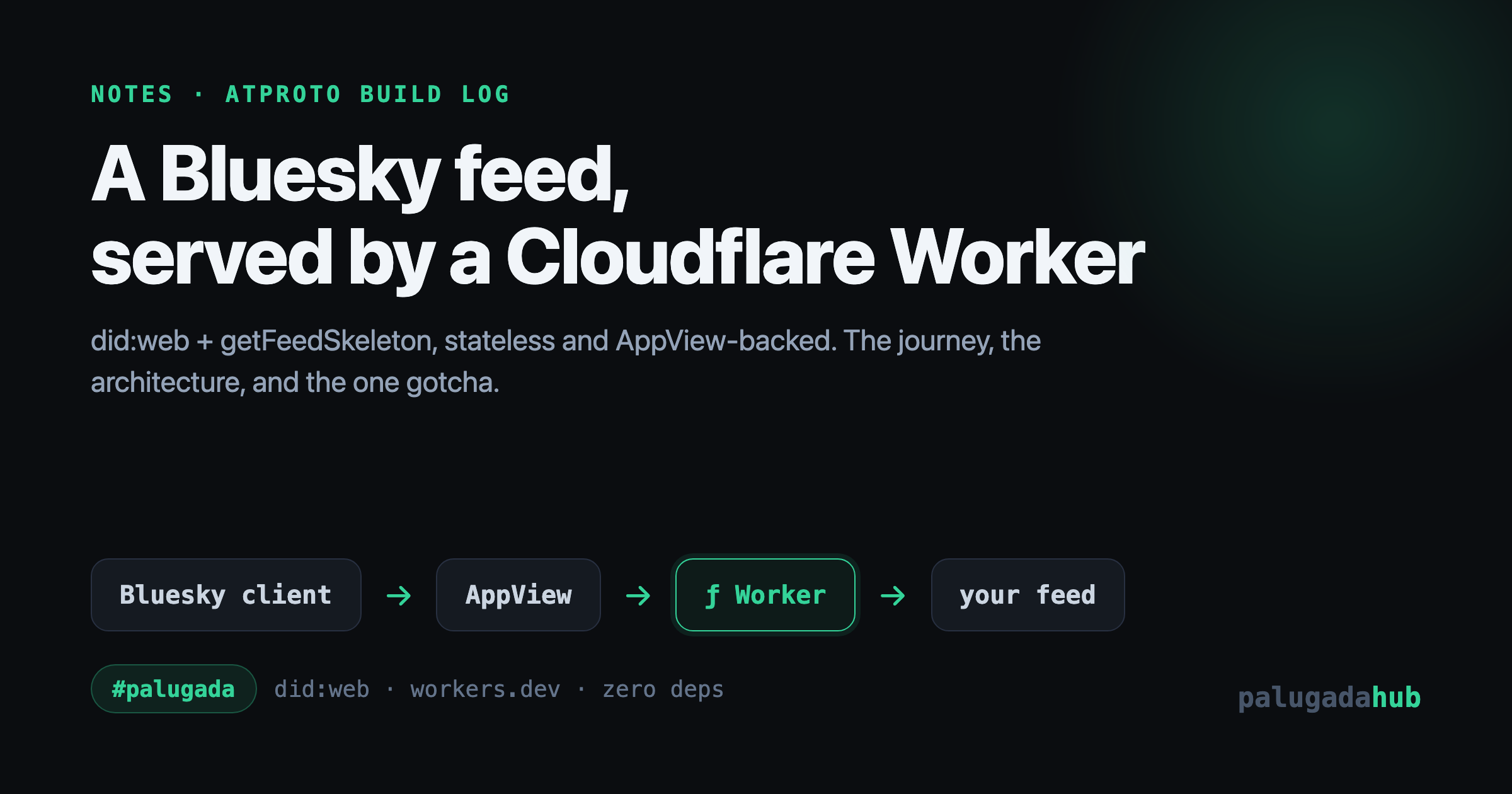
A Bluesky custom feed is not a stored list of posts. It is a small web service that answers one question: given a viewer, what post URIs should this feed show, in what order? Bluesky calls that the skeleton. Your service returns only the URIs. Bluesky's AppView then hydrates them into full posts (text, author, counts) for the client. You never store or serve post content, only the ordering logic.
That split is the whole trick. It means a feed generator can be tiny and stateless, which is exactly what we wanted.
Three things make a feed generator real on the network:
- A
did:webidentity so the network can find and trust your service. - An
app.bsky.feed.generatorrecord on an account, which is the published, subscribable feed. - An HTTP endpoint,
app.bsky.feed.getFeedSkeleton, that returns the ordered post URIs.
The journey, and the decisions
Cross-post or feed? Cross-posting is push. A feed is pull, and it compounds: every tagged post we ever make flows into it automatically, and anyone can subscribe once and keep getting it. We picked the feed.
Which account owns it? We reused the existing brand handle rather than spinning up a new identity, so the feed and the posts share one reputation.
How to curate? Two honest options. Run a firehose consumer, store posts in a database, and rank them. Or keep it stateless and derive the feed live from the AppView. The firehose is the "real" way and it scales to the whole network, but it needs a always-on consumer and storage. We did not need network-wide scope on day one. We needed our posts, tagged. So we chose stateless: the skeleton is built on demand from the AppView, filtered by a #palugada tag. No database, no firehose, no cron. The cost is that the feed only sees what the AppView already indexes, which for our own account is everything. A fair trade.
Where to host? A did:web identity is just https://<host>/.well-known/did.json. It can live anywhere with HTTPS. We deployed to a Cloudflare Worker. The first instinct was a custom subdomain, feed.palugadahub.com, but that needs a DNS record and a custom-domain binding. The *.workers.dev URL is already HTTPS and already ours, so did:web:palugada-feed-worker.ryandaaldo.workers.dev works with zero DNS. We shipped on that and left the custom domain as a later cosmetic upgrade. Ship the thing, prettify the URL later.
The flow
Here is what happens when someone opens the feed in their Bluesky app. The important part is that our Worker is only touched for the skeleton; Bluesky does the heavy lifting of turning URIs into posts.
at://brand/app.bsky.feed.generator/palugada → its serviceEndpoint is our did:web.GET /.well-known/did.json → points back at our Worker.getFeedSkeleton: query getAuthorFeed(brand), keep posts tagged #palugada, return just the URIs.And the publish side, which is how content gets into the feed:
#palugada tag facet.createRecord on the brand repo, tagged.getFeedSkeleton picks it up automatically. No redeploy, no manual step.The architecture, in detail
The Worker is one file. It answers three routes and holds no state.
GET /.well-known/did.jsonreturns the DID document. Itsidisdid:web:<host>and its single service entry, typeBskyFeedGenerator, points itsserviceEndpointback at the same host. Self-referential and that is correct: the document at a host claims to be the service at that host.GET /xrpc/app.bsky.feed.describeFeedGeneratoradvertises which feeds this service serves, by AT-URI.GET /xrpc/app.bsky.feed.getFeedSkeletonis the brain. It calls the public AppView'sgetAuthorFeedfor the brand DID, keeps the posts that carry the#palugadatag (checked both in the raw text and in the richtext tag facets, because a hashtag can be either), and returns their URIs with a numeric cursor for pagination. If nothing is tagged yet, it falls back to the account's recent posts so a fresh feed is never empty.
Because the skeleton is derived live, there is nothing to keep in sync. Tag a new post and it appears on the next refresh. Delete one and it falls out. The feed is a pure function of the account's tagged posts.
The publishers are two small Node scripts with no dependencies, talking to the PDS over plain XRPC.
publish_feed.mjsdoes a one-timeputRecordof anapp.bsky.feed.generatorrecord on the brand account. That record is what makes the feed show on the profile and become subscribable. Itsdidfield is the Worker'sdid:web, which is the link that ties the published feed to our service. Run it once; re-running is idempotent.publish_blog.mjsreads the blog markdown, and for each post builds a Bluesky post with the title, a link back to the article, and a#palugadatag. Both the link and the tag need richtext facets, which are byte-offset ranges into the text that mark where the link and hashtag are. It posts viacreateRecordand records what it sent in a small state file so it never double-posts.
The gotcha. The first batch of posts failed with grapheme too big (maximum 300, got 302). Bluesky's 300-character limit is counted in graphemes, not UTF-16 code units, and our long article slugs ate into the budget. The first naive builder capped the body at a character count and then appended the URL and tag on top, which could push past 300. The fix was to budget the other way around: compute the fixed tail (\n\n + URL + #palugada) first, then trim the title to whatever graphemes remain. Build the constraint, then fit the content into it, not the reverse.
Proving it end to end
A unit test that calls our own Worker proves our code. It does not prove the network accepts it. So the end-to-end test goes through Bluesky's real pipeline: it fetches our did.json, reads the generator record off the brand PDS, then calls the public AppView's app.bsky.feed.getFeed with the feed's AT-URI. That single call forces the AppView to resolve our did:web, call our getFeedSkeleton, and hydrate the posts, which is exactly what a real client does. The test then asserts the returned posts are real and hydrated (they have text, not just URIs), are all from the brand account, and all carry #palugada. Nine checks, all green. That is the difference between "my code returns the right JSON" and "Bluesky shows my feed."
Tradeoffs and what is next
The stateless design is the right call for a single-account, tag-curated feed, and it is honest about its limits. It cannot rank by engagement without extra calls, and it only sees what the AppView indexes. The day we want a network-wide #palugada feed (anyone's posts, not just ours), the swap is small: replace the getAuthorFeed call with searchPosts?q=%23palugada, or graduate to a firehose consumer with storage when search is not enough.
For now the feed is live, the blog flows into it, and the whole chain is verified against the real network. The pretty domain can come later. The thing works today, and that is the part that mattered.
Building an AI agent?
I'm packaging how I ship them into one kit. Early access:
AI Agent Starter Kit →